This is the multi-page printable view of this section. Click here to print.
Automated Annotation
- 1: Overview
- 2: Segment Anything 2 Tracker
- 3: AI Tools
1 - Overview
Automatic annotation in CVAT is a tool that you can use to automatically pre-annotate your data with pre-trained models.
CVAT can use models from the following sources:
- Pre-installed models.
- Models integrated from Hugging Face and Roboflow.
- Self-hosted models deployed with Nuclio.
- AI agent functions (SAM2 tracking) for CVAT Online and Enterprise.
The following table describes the available options:
| Self-hosted | Online | |
|---|---|---|
| Price | Free | See Pricing |
| Models | You have to add models | You can use pre-installed models |
| Hugging Face & Roboflow integration |
Not supported | Supported |
| AI Agent Functions | Supported (Enterprise) | Supported (SAM2 tracking available) |
See:
Running Automatic annotation
To start automatic annotation, do the following:
-
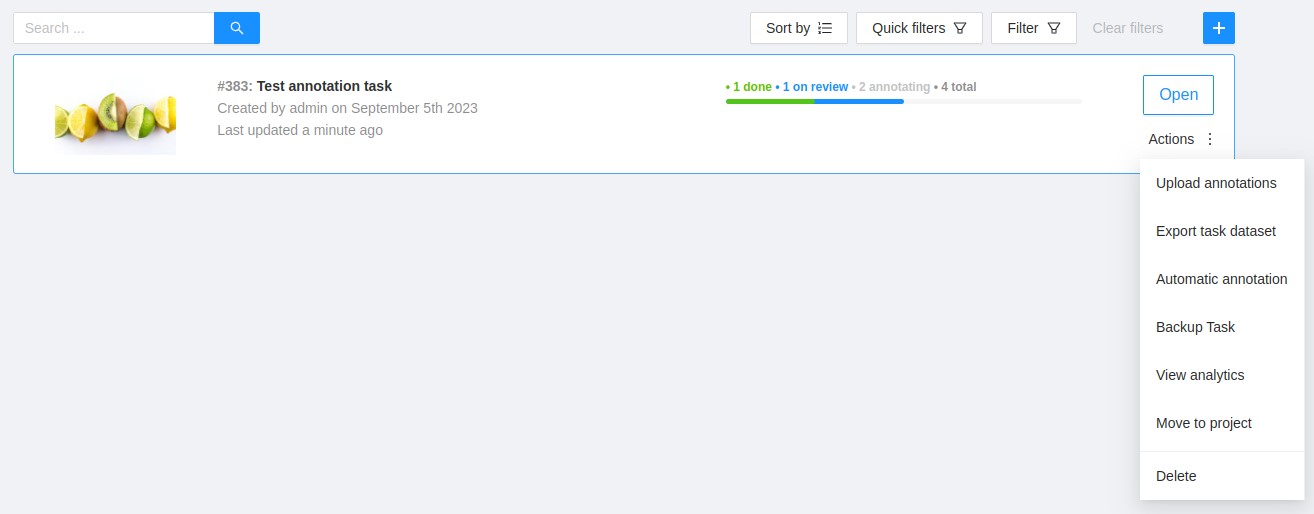
On the top menu, click Tasks.
-
Find the task you want to annotate and click Action > Automatic annotation.
-
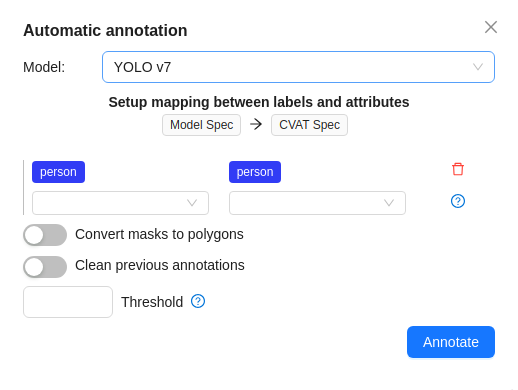
In the Automatic annotation dialog, from the drop-down list, select a model.
-
Match the labels of the model and the task.
-
(Optional) In case you need the model to return masks as polygons, switch toggle Return masks as polygons.
-
(Optional) In case you need to remove all previous annotations, switch toggle Clean old annotations.
-
(Optional) You can specify a Threshold for the model. If not provided, the default value from the model settings will be used.
-
Click Annotate.
CVAT will show the progress of annotation on the progress bar.

You can stop the automatic annotation at any moment by clicking cancel.
Labels matching
Each model is trained on a dataset and supports only the dataset’s labels.
For example:
- DL model has the label
car. - Your task (or project) has the label
vehicle.
To annotate, you need to match these two labels to give
CVAT a hint that, in this case, car = vehicle.
If you have a label that is not on the list of DL labels, you will not be able to match them.
For this reason, supported DL models are suitable only for certain labels.
To check the list of labels for each model, see Models papers and official documentation.
Models
Automatic annotation uses pre-installed and added models.
List of pre-installed models:
| Model | Description |
|---|---|
| Attributed face detection | Three OpenVINO models work together: |
| RetinaNet R101 | RetinaNet is a one-stage object detection model that utilizes a focal loss function to address class imbalance during training. Focal loss applies a modulating term to the cross entropy loss to focus learning on hard negative examples. RetinaNet is a single, unified network composed of a backbone network and two task-specific subnetworks. For more information, see: |
| Text detection | Text detector based on PixelLink architecture with MobileNetV2, depth_multiplier=1.4 as a backbone for indoor/outdoor scenes. For more information, see: |
| YOLO v3 | YOLO v3 is a family of object detection architectures and models pre-trained on the COCO dataset. For more information, see: |
| YOLO v7 | YOLOv7 is an advanced object detection model that outperforms other detectors in terms of both speed and accuracy. It can process frames at a rate ranging from 5 to 160 frames per second (FPS) and achieves the highest accuracy with 56.8% average precision (AP) among real-time object detectors running at 30 FPS or higher on the V100 graphics processing unit (GPU). For more information, see: |
Adding models from Hugging Face and Roboflow
In case you did not find the model you need, you can add a model of your choice from Hugging Face or Roboflow.
Note
You cannot add models from Hugging Face and Roboflow to self-hosted CVAT.For more information, see Streamline annotation by integrating Hugging Face and Roboflow models.
This video demonstrates the process:
2 - Segment Anything 2 Tracker
Overview
Segment Anything 2 is a segmentation model that allows fast and precise selection of any object in videos or images. SAM2 tracking is available in two implementations:
-
Nuclio SAM2 Tracker: Available only for Enterprise deployments. This is implemented as a serverless function deployed via Nuclio framework.
-
AI Agent SAM2 Tracker: Available for CVAT Online and Enterprise via auto-annotation (AA) functions that run on user-side agents. This brings SAM2 tracking capabilities to CVAT Online users who previously couldn’t access this feature.
It is strongly recommended to deploy the model using a GPU. Although it is possible to use a CPU-based version, it generally performs much slower and is suitable only for handling a single parallel request. The AI agent variant runs on user hardware, providing flexibility for GPU usage without server configuration requirements.
Unlike a regular tracking model, both SAM2 tracker implementations are designed to be applied to existing objects (polygons and masks) to track them forward for a specified number of frames.
How to install
Choose the installation method based on your platform and deployment needs.
Note
Nuclio SAM2 Tracker is only available in the Enterprise version. The AI agent variant brings SAM2 tracking to CVAT Online and Enterprise.Note
Both tracker implementations require the enhanced actions UI plugin, which is enabled by default. Usually, no additional steps are necessary on this.Nuclio SAM2 Tracker (CVAT Enterprise)
Docker
You can use existing scripts from the community repository
(./serverless/deploy_cpu.sh or ./serverless/deploy_gpu.sh).
To deploy the feature, simply run:
./serverless/deploy_gpu.sh "path/to/the/function"
Kubernetes
- You need to deploy the Nuclio function manually.
Note that this function requires a Redis storage configured to keep the tracking state.
You may use the same storage as
cvat_redis_ondiskuses. When running thenuclio deploycommand, make sure to provide the necessary arguments. The minimal command is:
nuctl deploy "path/to/the/function"
--env CVAT_FUNCTIONS_REDIS_HOST="<redis_host>"
--env CVAT_FUNCTIONS_REDIS_PORT="<redis_port>"
--env CVAT_FUNCTIONS_REDIS_PASSWORD="<redis_password>" # if applicable
AI Agent SAM2 Tracker (CVAT Online + Enterprise)
The AI agent implementation enables SAM2 tracking for CVAT Online users and provides an alternative deployment method for Enterprise customers. This approach runs the tracking model on user hardware via auto-annotation (AA) functions.
Prerequisites
- Python 3.10 or later
- Git
- CVAT Online account or Enterprise instance
- Optional: NVIDIA GPU with CUDA support for faster inference
Setup Instructions
-
Clone the CVAT repository:
git clone https://github.com/cvat-ai/cvat.git <CVAT_DIR> -
Install required dependencies:
pip install cvat-cli -r <CVAT_DIR>/ai-models/tracker/sam2/requirements.txtNote
If you encounter issues installing SAM2, refer to the SAM2 installation guide for solutions to common problems. -
Register the SAM2 function with CVAT:
cvat-cli --server-host <CVAT_BASE_URL> --auth <USERNAME>:<PASSWORD> \ function create-native "SAM2" \ --function-file=<CVAT_DIR>/ai-models/tracker/sam2/func.py -p model_id=str:<MODEL_ID> -
Run the AI agent:
cvat-cli --server-host <CVAT_BASE_URL> --auth <USERNAME>:<PASSWORD> \ function run-agent <FUNCTION_ID> \ --function-file=<CVAT_DIR>/ai-models/tracker/sam2/func.py -p model_id=str:<MODEL_ID>
Parameter Reference
<CVAT_BASE_URL>: Your CVAT instance URL (e.g.,https://app.cvat.ai)<USERNAME>and<PASSWORD>: Your CVAT credentials<FUNCTION_ID>: The ID returned by thefunction create-nativecommand<MODEL_ID>: A SAM2 model ID from Hugging Face Hub (e.g.,facebook/sam2.1-hiera-tiny)
Optional Parameters
- GPU Support: Add
-p device=str:cudato the agent command to use NVIDIA GPU acceleration - Organization Sharing: Add
--org <ORG_SLUG>to both commands to share the function with your organization
Agent Behavior and Resilience
The AI agent runs as a persistent process on your hardware, providing several advantages:
- Hardware Independence: Runs outside the CVAT server, enabling tracking without server-side GPU/Nuclio installation
- Isolation: Agent crashes don’t affect the server; requests are retried or reassigned automatically
- Resource Control: You control the computational resources (CPU/GPU) used for tracking
Important
Keep the agent process running to handle tracking requests. If the agent stops, active tracking operations will fail and need to be restarted.Version Requirements
- AI Agent SAM2 Tracker: Requires CVAT version 2.42.0 or later
- Classic SAM2 Tracker: Available in all Enterprise versions
- Python: Version 3.10 or later for AI agent setup
- GPU Support: Optional but recommended for both implementations
Usage
Both SAM2 tracker implementations provide similar user experiences with slight differences in the UI labels.
Running the Nuclio SAM2 Tracker
The nuclio tracker can be applied to any polygons and masks. To run the tracker on an object, open the object menu and click Run annotation action.
Alternatively, you can use a hotkey: select the object and press Ctrl + E (default shortcut). When the modal opened, in “Select action” list, choose Segment Anything 2: Tracker:
Running the AI Agent SAM2 Tracker
Once you have registered the SAM2 AI agent and it’s running, you’ll see “AI Tracker: SAM2” as an available action in the annotation UI for video shape tracking.
To use the AI agent tracker:
- Create or open a CVAT task from a video file or video-like sequence of images (all images must have the same dimensions)
- Open one of the jobs from the task
- Draw a mask or polygon around an object
- Right-click the object and choose “Run annotation action”
- Select “AI Tracker: SAM2” from the action list
- Specify the target frame and click Run
The usage flow parallels the existing annotation action interface but utilizes the remote AI agent rather than built-in serverless functions.
Tracking Process
Specify the target frame until which you want the object to be tracked, then click the Run button to start tracking. The process begins and may take some time to complete. The duration depends on the inference device, and the number of frames where the object will be tracked.
Once the process is complete, the modal window closes. You can review how the object was tracked. If you notice that the tracked shape deteriorates at some point, you can adjust the object coordinates and run the tracker again from that frame.
Running on multiple objects
Instead of tracking each object individually, you can track multiple objects simultaneously. To do this, click the Menu button in the annotation view and select the Run Actions option:
Alternatively, you can use a hotkey: just press Ctrl + E (default shortcut) when there are no objects selected. This opens the actions modal. In this case, the tracker will be applied to all visible objects of suitable types (polygons and masks). In the action list of the opened modal, select either:
- Segment Anything 2: Tracker (for the nuclio implementation)
- AI Tracker: SAM2 (for the AI agent implementation)
Specify the target frame until which you want the objects to be tracked, then click the Run button to start tracking. The process begins and may take some time to complete. The duration depends on the inference device, the number of simultaneously tracked objects, and the number of frames where the objects will be tracked.
Once the process finishes, you may close the modal and review how the objects were tracked. If you notice that the tracked shapes deteriorate, you can adjust their coordinates and run the tracker again from that frame (for a single object or for many objects).
Limitations and Considerations
AI Agent Limitations
When using the AI agent implementation, keep in mind:
- Single Agent Constraint: Only one agent can run at a time for any given tracking function. Running multiple agents may cause random failures as they compete for tracking states.
- Memory-based State: Tracking states are kept in agent memory. If the agent crashes or is shut down, all tracking states are lost and active tracking processes will fail.
- Agent-only Usage: Tracking functions can only be used via agents.
There is no equivalent of the
cvat-cli task auto-annotatecommand for tracking. - Rectangle Limitation: When using the AI Tools dialog (sidebar), only tracking functions that support rectangles will be selectable. The SAM2 tracker supports polygons and masks but not rectangles.
- Skeleton Tracking: Skeletons cannot currently be tracked by either implementation.
Tracker parameters
- Target frame: Objects will be tracked up to this frame. Must be greater than the current frame
- Convert polygon shapes to tracks: When enabled, all visible polygon shapes in the current frame will be converted to tracks before tracking begins. Use this option if you need tracks as the final output but started with shapes, produced for example by interactors (e.g. SAM2 or another one).
See Also
- SAM2 Object Tracking via AI Agent (Blog, July 31, 2025) - Detailed implementation and background information
- Auto-annotation Functions Documentation - Reference for creating custom tracking functions
- CVAT CLI Examples - Additional CLI usage examples
3 - AI Tools
Label and annotate your data in semi-automatic and automatic mode with the help of AI and OpenCV tools.
While interpolation is good for annotation of the videos made by the security cameras, AI and OpenCV tools are good for both: videos where the camera is stable and videos, where it moves together with the object, or movements of the object are chaotic.
See:
Interactors
Interactors are a part of AI and OpenCV tools.
Use interactors to label objects in images by creating a polygon semi-automatically.
When creating a polygon, you can use positive points or negative points (for some models):
- Positive points define the area in which the object is located.
- Negative points define the area in which the object is not located.

AI tools: annotate with interactors
To annotate with interactors, do the following:
- Click Magic wand
 , and go to the Interactors tab.
, and go to the Interactors tab. - From the Label drop-down, select a label for the polygon.
- From the Interactor drop-down, select a model (see Interactors models).
Click the Question mark to see information about each model: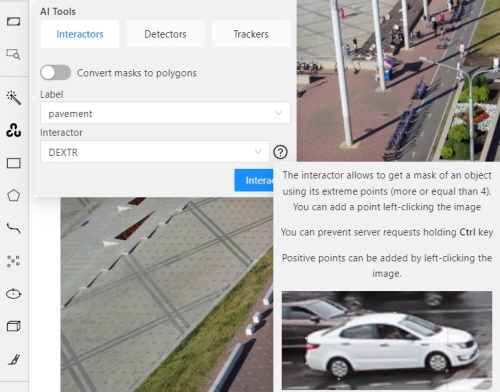
- (Optional) If the model returns masks, and you need to convert masks to polygons, use the Convert masks to polygons toggle.
- Click Interact.
- Use the left click to add positive points and the right click to add negative points.
Number of points you can add depends on the model. - On the top menu, click Done (or Shift+N, N).
AI tools: add extra points
Note
More points improve outline accuracy, but make shape editing harder. Fewer points make shape editing easier, but reduce outline accuracy.Each model has a minimum required number of points for annotation. Once the required number of points is reached, the request is automatically sent to the server. The server processes the request and adds a polygon to the frame.
For a more accurate outline, postpone request to finish adding extra points first:
- Hold down the Ctrl key.
On the top panel, the Block button will turn blue. - Add points to the image.
- Release the Ctrl key, when ready.
In case you used Mask to polygon when the object is finished, you can edit it like a polygon.
You can change the number of points in the polygon with the slider:

AI tools: delete points
To delete a point, do the following:
- With the cursor, hover over the point you want to delete.
- If the point can be deleted, it will enlarge and the cursor will turn into a cross.
- Left-click on the point.
OpenCV: intelligent scissors
To use Intelligent scissors, do the following:
-
On the menu toolbar, click OpenCV
 and wait for the library to load.
and wait for the library to load.
-
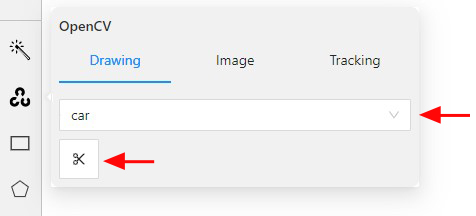
Go to the Drawing tab, select the label, and click on the Intelligent scissors button.
-
Add the first point on the boundary of the allocated object.
You will see a line repeating the outline of the object. -
Add the second point, so that the previous point is within the restrictive threshold.
After that a line repeating the object boundary will be automatically created between the points.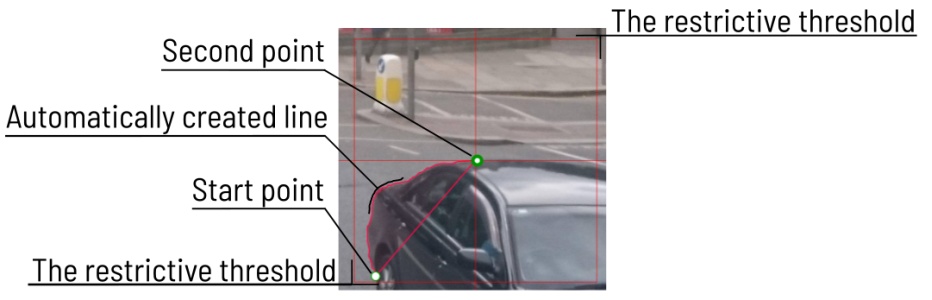
-
To finish placing points, on the top menu click Done (or N on the keyboard).
As a result, a polygon will be created.
You can change the number of points in the polygon with the slider:
To increase or lower the action threshold, hold Ctrl and scroll the mouse wheel.
During the drawing process, you can remove the last point by clicking on it with the left mouse button.
Settings
-
On how to adjust the polygon, see Objects sidebar.
-
For more information about polygons in general, see Annotation with polygons.
Interactors models
| Model | Tool | Description | Example |
|---|---|---|---|
| Segment Anything Model (SAM) | AI Tools | The Segment Anything Model (SAM) produces high quality object masks, and it can be used to generate masks for all objects in an image. It has been trained on a dataset of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks. For more information, see: |
 |
| Inside-Outside-Guidance (IOG) |
AI Tool | The model uses a bounding box and inside/outside points to create a mask. First of all, you need to create a bounding box, wrapping the object. Then you need to use positive and negative points to say the model where is a foreground, and where is a background. Negative points are optional. For more information, see: |
 |
| Intelligent scissors | OpenCV | Intelligent scissors is a CV method of creating a polygon by placing points with the automatic drawing of a line between them. The distance between the adjacent points is limited by the threshold of action, displayed as a red square that is tied to the cursor. For more information, see: |
 |
Detectors
Detectors are a part of AI tools.
Use detectors to automatically identify and locate objects in images or videos.
Labels matching
Each model is trained on a dataset and supports only the dataset’s labels.
For example:
- DL model has the label
car. - Your task (or project) has the label
vehicle.
To annotate, you need to match these two labels to give
DL model a hint, that in this case car = vehicle.
If you have a label that is not on the list of DL labels, you will not be able to match them.
For this reason, supported DL models are suitable only for certain labels.
To check the list of labels for each model, see Detectors models.
Annotate with detectors
To annotate with detectors, do the following:
-
Click Magic wand
, and go to the Detectors tab. -
From the Model drop-down, select model (see Detectors models).
-
From the left drop-down select the DL model label, from the right drop-down select the matching label of your task.
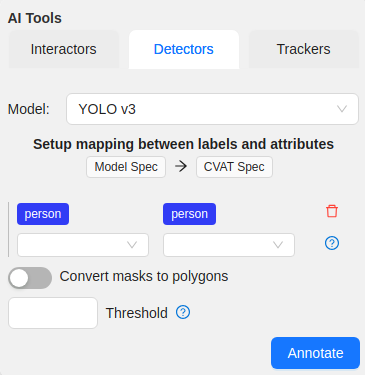
-
(Optional) If the model returns masks, and you need to convert masks to polygons, use the Convert masks to polygons toggle.
-
(Optional) You can specify a Threshold for the model. If not provided, the default value from the model settings will be used.
-
Click Annotate.
This action will automatically annotate one frame. For automatic annotation of multiple frames, see Automatic annotation.
Detectors models
| Model | Description |
|---|---|
| Mask RCNN | The model generates polygons for each instance of an object in the image. For more information, see: |
| Faster RCNN | The model generates bounding boxes for each instance of an object in the image. In this model, RPN and Fast R-CNN are combined into a single network. For more information, see: |
| YOLO v3 | YOLO v3 is a family of object detection architectures and models pre-trained on the COCO dataset. For more information, see: |
| Semantic segmentation for ADAS | This is a segmentation network to classify each pixel into 20 classes. For more information, see: |
| Faster RCNN with Tensorflow | Faster RCNN version with Tensorflow. The model generates bounding boxes for each instance of an object in the image. In this model, RPN and Fast R-CNN are combined into a single network. For more information, see: |
| RetinaNet | Pytorch implementation of RetinaNet object detection. For more information, see: |
| Face Detection | Face detector based on MobileNetV2 as a backbone for indoor and outdoor scenes shot by a front-facing camera. For more information, see: |
Trackers
Trackers are part of AI and OpenCV tools.
Use trackers to identify and label objects in a video or image sequence that are moving or changing over time.
AI tools: annotate with trackers
To annotate with trackers, do the following:
-
Click Magic wand
, and go to the Trackers tab.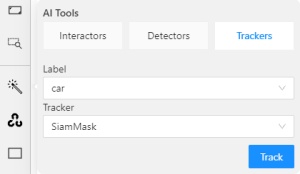
-
From the Label drop-down, select the label for the object.
-
From Tracker drop-down, select tracker.
-
Click Track, and annotate the objects with the bounding box in the first frame.
-
Go to the top menu and click Next (or the F on the keyboard) to move to the next frame.
All annotated objects will be automatically tracked.
When tracking
-
To enable/disable tracking, use Tracker switcher on the sidebar.
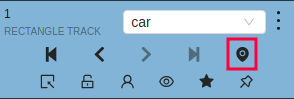
-
Trackable objects have an indication on canvas with a model name.

-
You can follow the tracking by the messages appearing at the top.

OpenCV: annotate with trackers
To annotate with trackers, do the following:
-
Create basic rectangle shapes or tracks for tracker initialization
-
On the menu toolbar, click OpenCV
and wait for the library to load. -
From Tracker drop-down, select tracker and Click Track
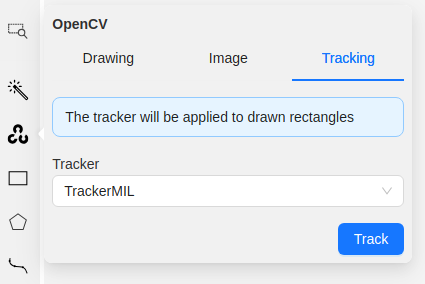
-
Annotation actions window will pop-up. Setup
Target frameandConvert rectangle shapes to tracksparameters and clickRunNote
Tracking will be applied to all filtered rectangle annotations.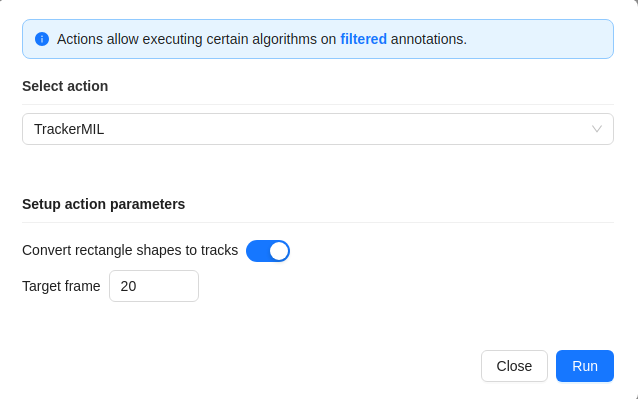
All annotated objects will be automatically tracked up until target frame parameter.
Trackers models
| Model | Tool | Description | Example |
|---|---|---|---|
| TrackerMIL | OpenCV | TrackerMIL model is not bound to labels and can be used for any object. It is a fast client-side model designed to track simple non-overlapping objects. For more information, see: |
|
| SiamMask | AI Tools | Fast online Object Tracking and Segmentation. The trackable object will be tracked automatically if the previous frame was the latest keyframe for the object. For more information, see: |
|
| Transformer Tracking (TransT) | AI Tools | Simple and efficient online tool for object tracking and segmentation. If the previous frame was the latest keyframe for the object, the trackable object will be tracked automatically. This is a modified version of the PyTracking Python framework based on Pytorch For more information, see: |
|
| SAM2 Tracker | AI Agent | Advanced object tracking and segmentation using Meta’s Segment Anything Model 2. Available for CVAT Online and Enterprise via AI agents. Supports polygons and masks with high precision tracking. Requires user-side agent setup with Python 3.10+. For more information, see: |
Example coming soon |
OpenCV: histogram equalization
Histogram equalization improves the contrast by stretching the intensity range.
It increases the global contrast of images when its usable data is represented by close contrast values.
It is useful in images with backgrounds and foregrounds that are bright or dark.
To improve the contrast of the image, do the following:
- In the OpenCV menu, go to the Image tab.
- Click on Histogram equalization button.
Histogram equalization will improve contrast on current and following frames.
Example of the result:

To disable Histogram equalization, click on the button again.