Automatic annotation
Automatic annotation in CVAT is a tool that you can use to automatically pre-annotate your data with pre-trained models.
CVAT can use models from the following sources:
- Pre-installed models.
- Models integrated from Hugging Face and Roboflow.
- Self-hosted models deployed with Nuclio.
The following table describes the available options:
| Self-hosted | Cloud | |
|---|---|---|
| Price | Free | See Pricing |
| Models | You have to add models | You can use pre-installed models |
| Hugging Face & Roboflow integration |
Not supported | Supported |
See:
Running Automatic annotation
To start automatic annotation, do the following:
-
On the top menu, click Tasks.
-
Find the task you want to annotate and click Action > Automatic annotation.
-
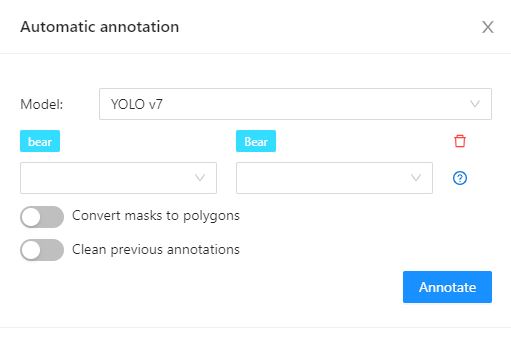
In the Automatic annotation dialog, from the drop-down list, select a model.
-
Match the labels of the model and the task.
-
(Optional) In case you need the model to return masks as polygons, switch toggle Return masks as polygons.
-
(Optional) In case you need to remove all previous annotations, switch toggle Clean old annotations.
-
Click Annotate.
CVAT will show the progress of annotation on the progress bar.

You can stop the automatic annotation at any moment by clicking cancel.
Labels matching
Each model is trained on a dataset and supports only the dataset’s labels.
For example:
- DL model has the label
car. - Your task (or project) has the label
vehicle.
To annotate, you need to match these two labels to give
CVAT a hint that, in this case, car = vehicle.
If you have a label that is not on the list of DL labels, you will not be able to match them.
For this reason, supported DL models are suitable only for certain labels.
To check the list of labels for each model, see Models papers and official documentation.
Models
Automatic annotation uses pre-installed and added models.
For self-hosted solutions, you need to install Automatic Annotation first and add models.
List of pre-installed models:
| Model | Description |
|---|---|
| Attributed face detection | Three OpenVINO models work together: |
| RetinaNet R101 | RetinaNet is a one-stage object detection model that utilizes a focal loss function to address class imbalance during training. Focal loss applies a modulating term to the cross entropy loss to focus learning on hard negative examples. RetinaNet is a single, unified network composed of a backbone network and two task-specific subnetworks. For more information, see: |
| Text detection | Text detector based on PixelLink architecture with MobileNetV2, depth_multiplier=1.4 as a backbone for indoor/outdoor scenes. For more information, see: |
| YOLO v3 | YOLO v3 is a family of object detection architectures and models pre-trained on the COCO dataset. For more information, see: |
| YOLO v5 | YOLO v5 is a family of object detection architectures and models based on the Pytorch framework. For more information, see: |
| YOLO v7 | YOLOv7 is an advanced object detection model that outperforms other detectors in terms of both speed and accuracy. It can process frames at a rate ranging from 5 to 160 frames per second (FPS) and achieves the highest accuracy with 56.8% average precision (AP) among real-time object detectors running at 30 FPS or higher on the V100 graphics processing unit (GPU). For more information, see: |
Adding models from Hugging Face and Roboflow
In case you did not find the model you need, you can add a model of your choice from Hugging Face or Roboflow.
Note, that you cannot add models from Hugging Face and Roboflow to self-hosted CVAT.
For more information, see Streamline annotation by integrating Hugging Face and Roboflow models.
This video demonstrates the process: