OpenCV and AI Tools
Label and annotate your data in semi-automatic and automatic mode with the help of AI and OpenCV tools.
While interpolation is good for annotation of the videos made by the security cameras, AI and OpenCV tools are good for both: videos where the camera is stable and videos, where it moves together with the object, or movements of the object are chaotic.
See:
Interactors
Interactors are a part of AI and OpenCV tools.
Use interactors to label objects in images by creating a polygon semi-automatically.
When creating a polygon, you can use positive points or negative points (for some models):
- Positive points define the area in which the object is located.
- Negative points define the area in which the object is not located.

AI tools: annotate with interactors
To annotate with interactors, do the following:
- Click Magic wand
 , and go to the Interactors tab.
, and go to the Interactors tab. - From the Label drop-down, select a label for the polygon.
- From the Interactor drop-down, select a model (see Interactors models).
Click the Question mark to see information about each model: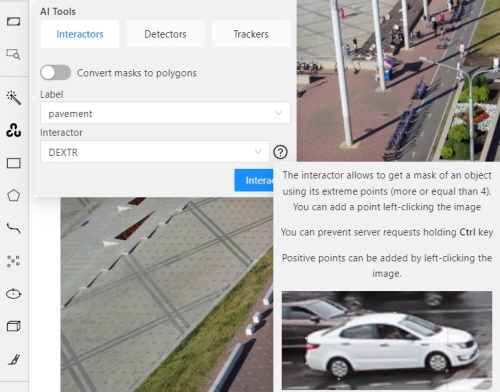
- (Optional) If the model returns masks, and you need to convert masks to polygons, use the Convert masks to polygons toggle.
- Click Interact.
- Use the left click to add positive points and the right click to add negative points.
Number of points you can add depends on the model. - On the top menu, click Done (or Shift+N, N).
AI tools: add extra points
Note: More points improve outline accuracy, but make shape editing harder. Fewer points make shape editing easier, but reduce outline accuracy.
Each model has a minimum required number of points for annotation. Once the required number of points is reached, the request is automatically sent to the server. The server processes the request and adds a polygon to the frame.
For a more accurate outline, postpone request to finish adding extra points first:
- Hold down the Ctrl key.
On the top panel, the Block button will turn blue. - Add points to the image.
- Release the Ctrl key, when ready.
In case you used Mask to polygon when the object is finished, you can edit it like a polygon.
You can change the number of points in the polygon with the slider:

AI tools: delete points
To delete a point, do the following:
- With the cursor, hover over the point you want to delete.
- If the point can be deleted, it will enlarge and the cursor will turn into a cross.
- Left-click on the point.
OpenCV: intelligent scissors
To use Intelligent scissors, do the following:
-
On the menu toolbar, click OpenCV
 and wait for the library to load.
and wait for the library to load.
-
Go to the Drawing tab, select the label, and click on the Intelligent scissors button.
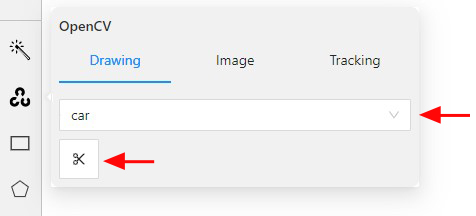
-
Add the first point on the boundary of the allocated object.
You will see a line repeating the outline of the object. -
Add the second point, so that the previous point is within the restrictive threshold.
After that a line repeating the object boundary will be automatically created between the points.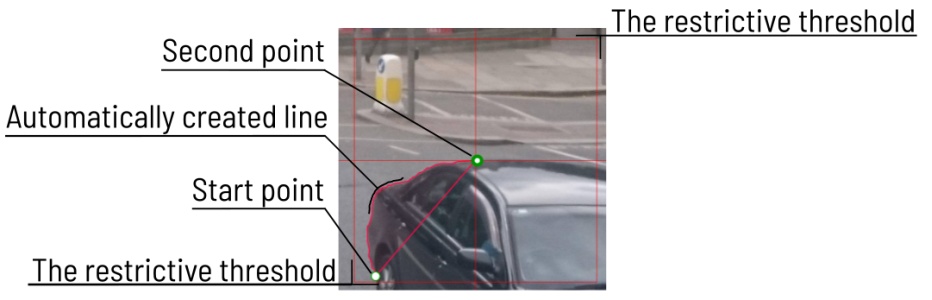
-
To finish placing points, on the top menu click Done (or N on the keyboard).
As a result, a polygon will be created.
You can change the number of points in the polygon with the slider:
To increase or lower the action threshold, hold Ctrl and scroll the mouse wheel.
During the drawing process, you can remove the last point by clicking on it with the left mouse button.
Settings
-
On how to adjust the polygon, see Objects sidebar.
-
For more information about polygons in general, see Annotation with polygons.
Interactors models
| Model | Tool | Description | Example |
|---|---|---|---|
| Segment Anything Model (SAM) | AI Tools | The Segment Anything Model (SAM) produces high quality object masks, and it can be used to generate masks for all objects in an image. It has been trained on a dataset of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks. For more information, see: |
 |
| Deep extreme cut (DEXTR) |
AI Tool | This is an optimized version of the original model, introduced at the end of 2017. It uses the information about extreme points of an object to get its mask. The mask is then converted to a polygon. For now this is the fastest interactor on the CPU. For more information, see: |
 |
| Feature backpropagating refinement scheme (f-BRS) |
AI Tool | The model allows to get a mask for an object using positive points (should be left-clicked on the foreground), and negative points (should be right-clicked on the background, if necessary). It is recommended to run the model on GPU, if possible. For more information, see: |
 |
| High Resolution Net (HRNet) |
AI Tool | The model allows to get a mask for an object using positive points (should be left-clicked on the foreground), and negative points (should be right-clicked on the background, if necessary). It is recommended to run the model on GPU, if possible. For more information, see: |
 |
| Inside-Outside-Guidance (IOG) |
AI Tool | The model uses a bounding box and inside/outside points to create a mask. First of all, you need to create a bounding box, wrapping the object. Then you need to use positive and negative points to say the model where is a foreground, and where is a background. Negative points are optional. For more information, see: |
 |
| Intelligent scissors | OpenCV | Intelligent scissors is a CV method of creating a polygon by placing points with the automatic drawing of a line between them. The distance between the adjacent points is limited by the threshold of action, displayed as a red square that is tied to the cursor. For more information, see: |
 |
Detectors
Detectors are a part of AI tools.
Use detectors to automatically identify and locate objects in images or videos.
Labels matching
Each model is trained on a dataset and supports only the dataset’s labels.
For example:
- DL model has the label
car. - Your task (or project) has the label
vehicle.
To annotate, you need to match these two labels to give
DL model a hint, that in this case car = vehicle.
If you have a label that is not on the list of DL labels, you will not be able to match them.
For this reason, supported DL models are suitable only for certain labels.
To check the list of labels for each model, see Detectors models.
Annotate with detectors
To annotate with detectors, do the following:
-
Click Magic wand
, and go to the Detectors tab. -
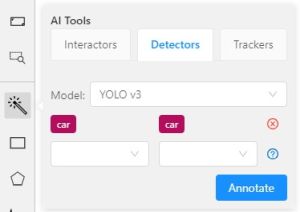
From the Model drop-down, select model (see Detectors models).
-
From the left drop-down select the DL model label, from the right drop-down select the matching label of your task.
-
(Optional) If the model returns masks, and you need to convert masks to polygons, use the Convert masks to polygons toggle.
-
Click Annotate.
This action will automatically annotate one frame. For automatic annotation of multiple frames, see Automatic annotation.
Detectors models
| Model | Description |
|---|---|
| Mask RCNN | The model generates polygons for each instance of an object in the image. For more information, see: |
| Faster RCNN | The model generates bounding boxes for each instance of an object in the image. In this model, RPN and Fast R-CNN are combined into a single network. For more information, see: |
| YOLO v3 | YOLO v3 is a family of object detection architectures and models pre-trained on the COCO dataset. For more information, see: |
| YOLO v5 | YOLO v5 is a family of object detection architectures and models based on the Pytorch framework. For more information, see: |
| Semantic segmentation for ADAS | This is a segmentation network to classify each pixel into 20 classes. For more information, see: |
| Mask RCNN with Tensorflow | Mask RCNN version with Tensorflow. The model generates polygons for each instance of an object in the image. For more information, see: |
| Faster RCNN with Tensorflow | Faster RCNN version with Tensorflow. The model generates bounding boxes for each instance of an object in the image. In this model, RPN and Fast R-CNN are combined into a single network. For more information, see: |
| RetinaNet | Pytorch implementation of RetinaNet object detection. For more information, see: |
| Face Detection | Face detector based on MobileNetV2 as a backbone for indoor and outdoor scenes shot by a front-facing camera. For more information, see: |
Trackers
Trackers are part of AI and OpenCV tools.
Use trackers to identify and label objects in a video or image sequence that are moving or changing over time.
AI tools: annotate with trackers
To annotate with trackers, do the following:
-
Click Magic wand
, and go to the Trackers tab.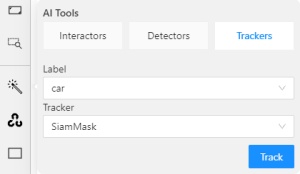
-
From the Label drop-down, select the label for the object.
-
From Tracker drop-down, select tracker.
-
Click Track, and annotate the objects with the bounding box in the first frame.
-
Go to the top menu and click Next (or the F on the keyboard) to move to the next frame.
All annotated objects will be automatically tracked.
OpenCV: annotate with trackers
To annotate with trackers, do the following:
-
On the menu toolbar, click OpenCV
and wait for the library to load. -
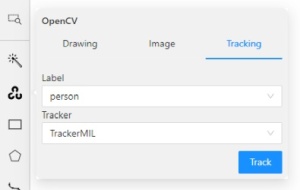
Go to the Tracker tab, select the label, and click Tracking.
-
From the Label drop-down, select the label for the object.
-
From Tracker drop-down, select tracker.
-
Click Track.
-
To move to the next frame, on the top menu click the Next button (or F on the keyboard).
All annotated objects will be automatically tracked when you move to the next frame.
When tracking
-
To enable/disable tracking, use Tracker switcher on the sidebar.
-
Trackable objects have an indication on canvas with a model name.

-
You can follow the tracking by the messages appearing at the top.
Trackers models
| Model | Tool | Description | Example |
|---|---|---|---|
| TrackerMIL | OpenCV | TrackerMIL model is not bound to labels and can be used for any object. It is a fast client-side model designed to track simple non-overlapping objects. For more information, see: |
|
| SiamMask | AI Tools | Fast online Object Tracking and Segmentation. The trackable object will be tracked automatically if the previous frame was the latest keyframe for the object. For more information, see: |
|
| Transformer Tracking (TransT) | AI Tools | Simple and efficient online tool for object tracking and segmentation. If the previous frame was the latest keyframe for the object, the trackable object will be tracked automatically. This is a modified version of the PyTracking Python framework based on Pytorch For more information, see: |
OpenCV: histogram equalization
Histogram equalization improves the contrast by stretching the intensity range.
It increases the global contrast of images when its usable data is represented by close contrast values.
It is useful in images with backgrounds and foregrounds that are bright or dark.
To improve the contrast of the image, do the following:
- In the OpenCV menu, go to the Image tab.
- Click on Histogram equalization button.
Histogram equalization will improve contrast on current and following frames.
Example of the result:

To disable Histogram equalization, click on the button again.